
在 AI21,我们正与各行各业的开发者合作,利用我们的任务特定模型和 RAG 引擎为其问答应用提供支持。大多数开发者希望构建能够基于特定知识体系(例如其公司文档)提供答案的应用。这种方法被称为检索增强生成(RAG)。RAG 通过保持答案与上下文相关来减少幻觉。
构建基于 RAG 的问答应用可能很复杂。开发者需要完成多个步骤来整合 RAG 流水线,包括
- 连接到您的文档知识库
- 将这些文档分段并嵌入到向量存储中
- 设置语义搜索功能,以便向向量存储发送查询
- 从向量存储中检索相关上下文,并将其传递给 LLM 以生成增强的响应
AI21 的 RAG 引擎和 Contextual Answers 任务特定模型 (TSM) 负责处理这些步骤。RAG 引擎使开发者无需手动设置即可快速部署高性能、可扩展的 RAG 流水线。得益于 Contextual Answers TSM,生成的回答可靠且准确,并且成本远低于领先的基础模型。

对于希望构建生产级 RAG 应用的开发者,本文将指导您创建由 AI21 的 RAG 引擎和 Contextual Answers TSM 提供支持的自有问答应用。该应用的沙盒版本可在此处获取。
在本文中,我们将
- 介绍任务特定模型 (TSM) 的概念,并评估 AI21 的 Contextual Answers TSM 在基于 RAG 的问答方面与其他模型的对比
- 解释我们的 RAG 引擎如何为部署 RAG 流水线提供一个简单而强大的解决方案
- 提供循序渐进的说明,帮助您构建和运行由 AI21 提供支持的自有问答应用
什么是 TSM?
AI21 的任务特定模型 (TSM) 是经过专门训练的小型语言模型,旨在在特定用例中表现出色。TSM 专注于常见的用例,例如可靠问答、摘要和文本编辑。
Contextual Answers TSM 为 RAG 问答应用提供了多种优势
- 在专业问答中具有更高准确性
Contextual Answers TSM 的幻觉率非常低,尤其是与其他基础模型相比。它非常擅长识别上下文与问题之间的不相关性,并返回“答案不在文档中”,而不是凭空捏造答案。需要的提示工程较少,从而带来更好的用户体验。

Contextual Answers TSM 的“良好”答案率达到了 68%。
事实上,Contextual Answers TSM 在测试中优于 Claude 2.1,其“良好”答案率高出 12%。“良好”答案定义为事实正确、流畅且全面。
- 提高安全性
由于 Contextual Answers TSM 经过训练用于生成可靠的响应,因此它更能抵御提示注入和其他恶意攻击。
- 与其他基础模型相比,延迟和成本更低
大规模使用 GPT-4 等基础模型可能非常昂贵。Contextual Answers TSM 的使用和扩展成本显著降低。

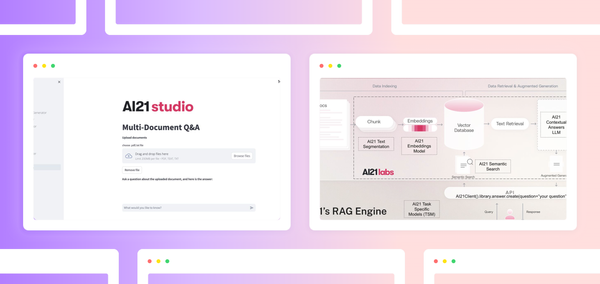
什么是 AI21 的 RAG 引擎?
构建 RAG 流水线可能看起来很简单,但同时保持性能并进行扩展却很困难。当开发者使用各种不同的模型和流程时,协调起来具有挑战性。多个方面会影响 RAG 性能,包括
- 分块和嵌入过程的效率
- 支持多种文件类型
- 随着数据量增加而扩展
AI21 的 RAG 引擎提供了一个可通过 API 访问的可扩展一体化解决方案。Contextual Answers TSM 无缝接入 RAG 引擎,构建了端到端流水线。
在这篇博客文章中了解更多关于 RAG 引擎的信息。
架构图

在 Streamlit Community Cloud 上
您可以在 Streamlit Community Cloud 上查看该应用的托管版本 此处。请继续阅读,了解如何构建您自己的应用。
构建您自己的由任务特定小型语言模型提供支持的问答应用
此应用允许您上传 PDF 或 .txt 文件,并将上传的文档作为知识库进行提问。
要在本地构建并运行我们应用的您自己的版本,请克隆 GitHub 仓库并使用您的 AI21 凭据。
-
请求您的 AI21 Studio 账户:https://studio.ai21.com/login
-
找到您的 AI21 API 密钥:https://studio.ai21.com/account/api-key
-
在
.streamlit文件夹中创建secrets.toml文件并添加您的凭据,将<YOUR_API_KEY>替换为您的 AI21 API 密钥[api-keys] ai21-api-key = "<YOUR_API_KEY>" -
安装 requirements.txt 中列出的所有依赖项,包括 AI21 Labs Python SDK
-
通过在您的控制台中输入 streamlit run Welcome.py 来运行 Welcome.py
-
运行上述命令后,AI21 Studio Streamlit 应用的欢迎页面应在您的浏览器中打开
-
导航到多文档问答页面
应用拆解
-
导入 AI21 库并加载凭据
# import AI21 SDK library from ai21 import AI21Client # initiate AI21 client with your API key client = AI21Client(api_key=st.secrets['api-keys']['ai21-api-key']) -
将文件上传到带有文档标签的 AI21 文档库(可选)
# Streamlit file uploader widget uploaded_files = st.file_uploader("choose .pdf/.txt file", accept_multiple_files=True, type=["pdf", "text", "txt"], key="a") # upload the files to AI21 RAG Engine library for uploaded_file in uploaded_files: client.library.files.create(file_path=uploaded_file, labels=label) -
使用 AI21 Contextual Answers 模型对上传的文档进行提问
# Streamlit text input widget question = st.text_input(label="Question:", value="Your Question") # send your question to AI21 Contextual Answers LLM and getting back the response response = client.library.answer.create(question=question, label=label)
总结
我们希望本指南能让您轻松构建一个可靠的、基于上下文的问答应用。通过此应用,用户可以与复杂的知识体系进行交互,以改进客户支持、合同分析、产品优化等工作流程。
对于 Streamlit 用户,AI21 很高兴提供扩展的入门捆绑包,其中包括用于 AI21 Studio 实验场的免费积分以及一次指导性的 1 对 1 会话,用于讨论您的用例并帮助您入门。
如果您有任何问题,请在下方评论区留言,联系 studio@ai21.com,或创建 GitHub Issue。



评论
在我们的论坛中继续讨论 →