
记得第一次玩AI图像生成器时有多酷吗?那些拥有两千万根手指和噩梦般吃意大利面的图片不仅仅有趣,它们无意中揭示了一个事实:哦!AI模型和我们一样聪明。像我们一样,它们也很难画出手。

AI模型迅速变得更加复杂,但现在模型太多了。而且——再说一次——就像我们一样,有些模型在某些任务上比其他模型做得更好。以文本生成为例。尽管Llama、Gemma和Mistral都是LLMs,但有些模型更擅长生成代码,而另一些则更擅长头脑风暴、编码或创意写作。它们根据提示提供不同的优势,因此在你的AI应用中包含不止一个模型可能是有意义的。
但如何在不重复代码的情况下将所有这些模型集成到你的应用中?如何使你的AI使用更具模块化,从而更容易维护和扩展?这就是API发挥作用的地方,它可以提供一套标准化的指令,用于跨不同技术进行通信。
在这篇博文中,我们将探讨如何使用 Replicate 和 Streamlit 创建一个应用,让你通过一个API调用来配置和提示不同的LLMs。别担心——当我说“应用”时,我不是指你需要启动一个完整的Flask服务器,或繁琐地配置你的路由,或担心CSS。Streamlit已经为你搞定了 😉
继续阅读以了解
- 什么是 Replicate
- 什么是 Streamlit
- 如何构建一个 Replicate 聊天机器人 Streamlit 应用演示
- 以及使用 Replicate 的最佳实践
不想阅读?这里有一些其他方式来探索这个演示
- 在 Streamlit Cookbook 仓库中找到代码 此处
- 观看 Streamlit 高级开发者布道师 Chanin Nantasenamat 和 Replicate 创始设计师 Zeke Sikelianos 的视频演练 此处
- 查看应用的部署版本 此处 或查看下方的嵌入式应用(点击全屏查看)
什么是 Replicate?
Replicate 是一个平台,使开发者能够通过 CLI、API 或 SDK 部署、微调和访问开源AI模型。该平台使将AI能力以编程方式集成到软件应用中变得容易。
Replicate 上可用的模型
- 文本:像 Llama 3 这样的模型可以根据输入提示生成连贯且上下文相关的文本。
- 图像:像 stable diffusion 这样的模型可以从文本提示生成高质量图像。
- 语音:像 whisper 这样的模型可以将语音转换为文本,而像 xtts-v2 这样的模型可以生成听起来自然的语音。
- 视频:像 animate-diff 或 stable diffusion 的变体(如 videocrafter)可以分别从文本和图像提示生成和/或编辑视频。
当一起使用时,Replicate 允许你开发多模态应用,这些应用可以接受各种格式(无论是文本、图像、语音还是视频)的输入并生成输出。
什么是 Streamlit?
Streamlit 是一个开源的 Python 框架,只需几行代码即可构建高度交互的应用。Streamlit 集成了所有最新的生成式AI工具,例如任何LLM、向量数据库或各种AI框架,如 LangChain、LlamaIndex 或 Weights & Biases。Streamlit 的聊天元素使得与AI交互变得特别容易,因此你可以构建能够“与你的数据对话”的聊天机器人。
结合像 Replicate 这样的平台,Streamlit 允许你创建生成式AI应用,而无需任何应用设计的开销。
要了解更多关于 Streamlit 的信息,请查看 101 指南。
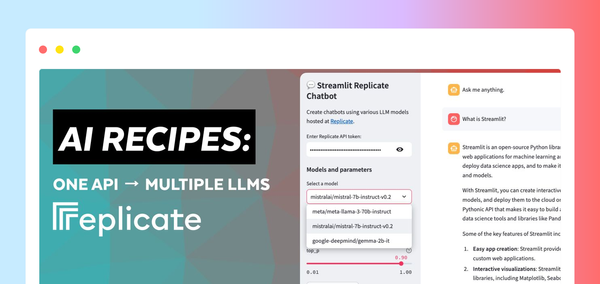
尝试应用示例:Replicate + Streamlit
但不要只听我说的。亲自试用这个应用或观看视频演练,看看你的想法。
在这个演示中,你将使用 Replicate 启动一个 Streamlit 聊天机器人应用。该应用使用一个API访问三个不同的LLMs,并调整温度(temperature)和 top-p 等参数。这些参数会影响AI生成文本的随机性和多样性,以及选择 token 的方法。
温度控制模型如何选择 token。较低的温度使模型更保守,倾向于常见和“安全”的词语。相反,较高的温度鼓励模型通过选择概率较低的 token 来承担更多风险,从而产生更具创意的输出。
什么是 top-p?
也称为“核采样”(nucleus sampling)——是另一种调整随机性的方法。它通过在 top-p 值增加时考虑更广泛的 token 集合来工作。较高的 top-p 值会导致采样的 token 范围更广,产生更多样的输出。
前提条件
- Python 版本 >=3.8, !=3.9.7
- 一个 Replicate API 密钥
(请注意,访问超出免费试用限制的功能需要支付方式。)
环境设置
本地设置
- 克隆 Cookbook 仓库:
git clonehttps://github.com/streamlit/cookbook.git - 从 Cookbook 根目录,进入 Replicate 应用示例目录:
cd recipes/replicate - 将你的 Replicate API 密钥添加到
.streamlit/secrets_template.toml文件中 - 将文件名从
secrets_template.toml更新为secrets.toml:mv .streamlit/secrets_template.toml .streamlit/secrets.toml
(要了解有关 Streamlit 中密钥处理的更多信息,请参阅此处的文档。) - 创建一个虚拟环境:
python -m venv replicatevenv - 激活虚拟环境:
source replicatevenv/bin/activate - 安装依赖项:
pip install -r requirements.txt
- 从 GitHub 上的 Cookbook 仓库中,通过选择
Code按钮中的Codespaces选项来创建一个新的 codespace - codespace 生成后,将你的 Replicate API 密钥添加到
recipes/replicate/.streamlit/secrets_template.toml文件中 - 将文件名从 `secrets_template.toml` 更新为
secrets.toml
(要了解有关 Streamlit 中密钥处理的更多信息,请参阅此处的文档。) - 从 Cookbook 根目录,进入 Replicate 应用示例目录:
cd recipes/replicate - 安装依赖项:
pip install -r requirements.txt

使用 Replicate 运行一个文本生成模型
- 在
recipes/replicate目录中创建一个名为replicate_hello_world.py的文件 - 将以下代码添加到文件中
import replicate import toml import os # Read the secrets from the secrets.toml file with open(".streamlit/secrets.toml", "r") as f: secrets = toml.load(f) # Create an environment variable for the Replicate API token os.environ['REPLICATE_API_TOKEN'] = secrets["REPLICATE_API_TOKEN"] # Run a model for event in replicate.stream("meta/meta-llama-3-8b", input={"prompt": "What is Streamlit?"},): print(str(event), end="") - 运行脚本:
python replicate_hello_world.py
你应该会看到模型生成的文本输出。
要了解有关 Replicate 模型及其工作原理的更多信息,你可以参阅此处的文档。其核心是,Replicate 的“模型”指的是一个经过训练、打包并发布的软件程序,它接受输入并返回输出。
在这个特定案例中,模型是 meta/meta-llama-3-8b,输入是 "prompt": "What is Streamlit?"。当你运行脚本时,会调用 Replicate 的端点,打印出的文本是通过 Replicate 从模型返回的输出。
运行 Replicate Streamlit 聊天机器人应用演示
要运行演示应用,请从 recipes/replicate 应用示例目录中使用 Streamlit CLI:streamlit run streamlit_app.py。
运行此命令会将应用部署到 localhost 上的一个端口。当你访问此位置时,应该能看到一个 Streamlit 应用正在运行。

你可以使用此应用通过 Replicate 提示不同的 LLMs,并根据你提供的配置生成文本。
一个用于多个 LLM 模型的通用 API
使用 Replicate 意味着你可以用一个API提示多个开源 LLMs,这有助于简化 AI 集成到现代软件流程中。
这是通过以下代码块实现的
for event in replicate.stream(
model,
input={
"prompt": prompt_str,
"prompt_template": r"{prompt}",
"temperature": temperature,
"top_p": top_p,
},
):
yield str(event)model、temperature 和 top p 配置由用户通过 Streamlit 的输入控件提供。Streamlit 的聊天元素使在你的应用中集成聊天机器人功能变得容易。最棒的是,你不需要了解 JavaScript 或 CSS 来实现和样式化这些组件——Streamlit 开箱即用地提供了所有这些。
Replicate 最佳实践
为提示使用最佳模型
Replicate 提供了一个API端点来搜索公共模型。你还可以在他们的网站上探索特色模型和用例。这使得很容易找到适合你特定需求的模型。
不同的模型有不同的性能特征。根据你对准确性和速度的需求,使用适当的模型。
使用 webhooks、流式传输和图像 URL 提升性能
Replicate 的输出数据仅在一小时内可用。使用 webhooks 将数据保存到你自己的存储中。你还可以设置 webhooks 来处理模型的异步响应。这对于构建可扩展的应用至关重要。
可能时利用流式传输。一些模型支持流式传输,让你在生成过程中获取部分结果。这对于实时应用来说是理想的。
使用图像 URL 比使用经过 base 64 编码的上传图像提供了更高的性能。
用 Streamlit 释放 AI 的潜力
有了 Streamlit,数月甚至数年的应用设计工作被简化为仅几行 Python 代码。它是展示你最新 AI 发明的完美框架。
在Streamlit Cookbook 中,使用其他 AI 应用示例快速上手并运行。(别忘了在论坛中向我们展示你正在构建什么!)
祝你 Streamlit 使用愉快!🎈

评论
在我们的论坛中继续讨论 →